
Designing Local LLMs on Azure for Security, Reliability, and Control

In a previous post, I looked at what it really means to run LLMs locally from the perspective of a .NET developer. We explored why teams still care about local models despite the raw capability gap with GPT-5, how privacy, cost, latency, and compliance drive that decision, and how Microsoft.Extensions.AI makes it possible to build hybrid systems that switch cleanly between cloud models and a locally hosted runtime like Ollama. That discussion was deliberately developer-centric, focused on code, abstractions, and the trade-offs you experience when an application decides whether to call GPT-5 or keep data on the machine.
This article looks at a different problem entirely. Instead of asking how to run a model locally on a workstation, we are going to look at what it takes to design and operate a local-feeling LLM platform on Azure itself. Not a public API call wrapped in configuration, and not a developer experiment, but a properly isolated, private, identity-secured LLM that lives inside your virtual network and behaves like an internal service. The focus here is not provider abstraction, but architecture, private endpoints, managed identity, governance, and operational discipline. In other words, how you move from local models in a .NET app to LLMs as internal infrastructure
Building a Truly Local LLM Platform on Azure
You might start experimenting with LLMs by calling a public API and wiring the response into an application. That phase is useful, but it ends quickly. As soon as the model touches real data, supports real users, or sits behind a regulated workflow, the questions change. Where does the data go? Who can access the model? How do we control behaviour over time? How do we prevent one bad prompt from blowing the budget?
This is where the idea of a local LLM becomes important.
Local does not mean on your laptop. It means the model is treated as infrastructure. It lives inside your security boundary, participates in your identity model, respects your network topology, and is observable and governable like any other internal service. Azure gives you the primitives to do this, but it does not assemble them for you. That is your job.
This article walks through that assembly in detail.
Why Azure Is a Good Fit for Local Style LLMs
Azure is unusually strong in this space because its AI offerings inherit the same enterprise primitives as storage, databases, and messaging. Azure OpenAI Service is not just a hosted model endpoint. It is a first-class Azure resource that supports private networking, Entra ID authentication, regional isolation, and resource level RBAC. That combination is rare. Many managed LLM platforms stop at API keys and IP allow lists. Azure lets you go further and treat inference as a zero trust internal dependency.
The consequence is architectural. You can design your system so that no developer, no CI pipeline, and no external system can talk to the model unless they are explicitly granted permission and are physically inside your network boundary.
That is what local really means in the cloud.
The Network Is the Product Boundary
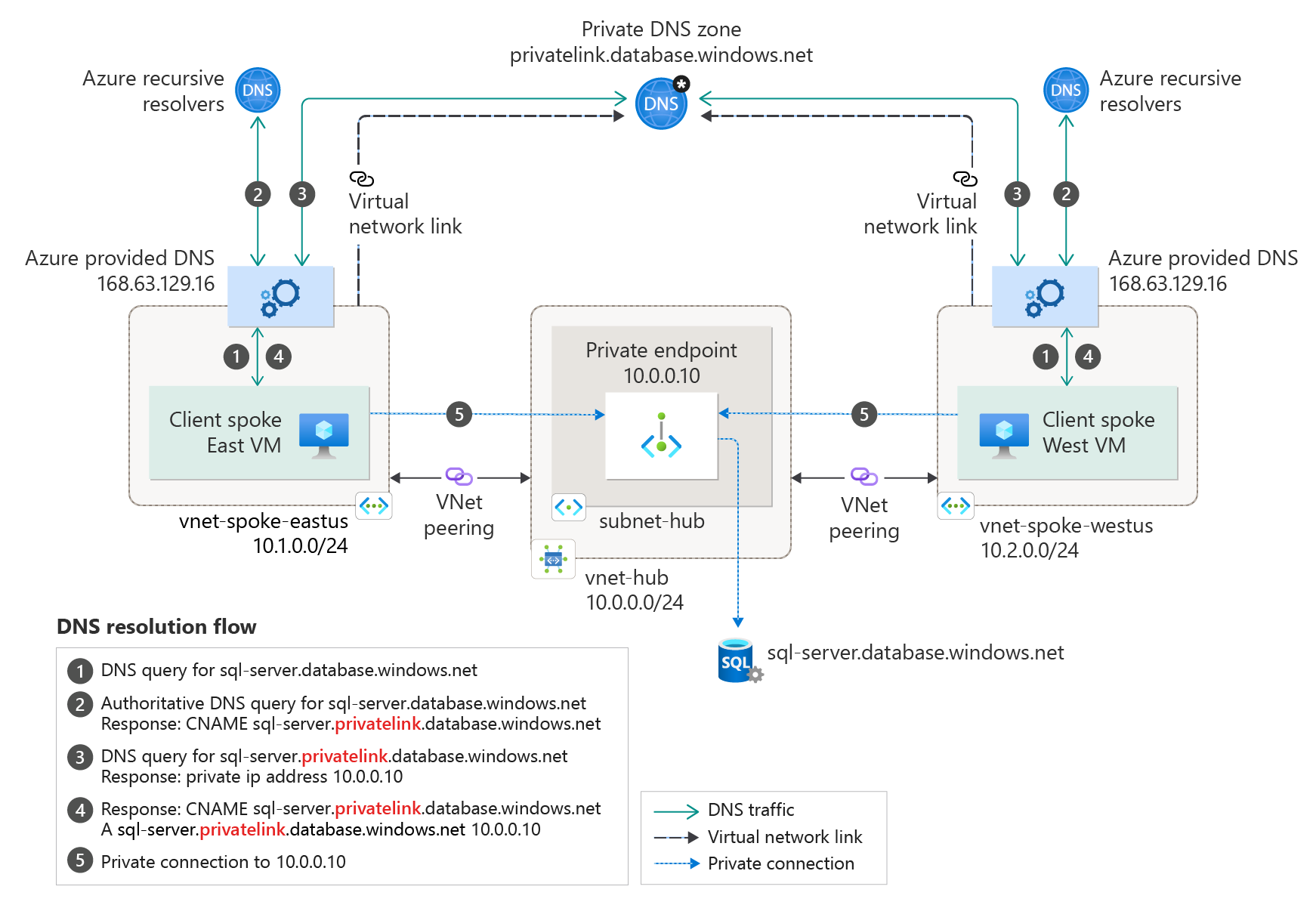
The most important decision you will make is to disable public access to the model endpoint and rely exclusively on a private endpoint. Everything else builds on this.
When you enable a private endpoint for Azure OpenAI, Azure assigns a private IP address inside your virtual network and publishes a private DNS record that overrides the public hostname. From that moment on, name resolution itself enforces isolation. Calls from outside your VNet do not resolve.
This is stronger than firewall rules. There is no public surface to attack.
In practice, this means your application workloads must also live inside the VNet, or be integrated into it. Azure Container Apps with VNet injection, AKS, and App Service with regional VNet integration all work. What matters is that the call path from application to model never leaves the private network.
If you get this wrong, everything else is compromised.
Identity Is Not Optional
Using API keys for LLM access is the AI equivalent of storing database passwords in config files. It works, but its not safe.
Azure OpenAI supports Entra ID authentication, and you should consider this mandatory. With managed identity, your application authenticates using its own identity, not a shared secret. Access can be granted, audited, and revoked using the same mechanisms you already trust for storage accounts and message brokers. This has a subtle but powerful effect on system design. Instead of thinking in terms of “who has the key”, you start thinking in terms of “which workload is allowed to perform inference”. That aligns naturally with least privilege design. It also enables something important later. You can run multiple internal LLM facing services, each with different permissions, quotas, or even different model deployments, without duplicating secrets or configuration.
Choosing Models
A common early mistake is to pick the largest, most capable model and build everything around it. This creates two problems. Cost becomes unpredictable, and latency becomes variable. In a local platform setup, you should think in terms of tiers. A fast, smaller model for classification, routing, extraction, and guardrail checks. A stronger model for reasoning heavy tasks. Possibly a specialised model for summarisation or transformation. Azure OpenAI allows you to deploy multiple models side by side. The key is to treat model selection as an architectural decision, not a prompt detail hidden in application code.
When you later introduce routing or fallback logic, this separation becomes invaluable.
The LLM Should Never Be Called Directly
If every feature team writes their own prompt and calls the model directly, you lose control almost immediately. Prompts drift. Behaviour changes subtly. Costs explode in strange places. Nobody owns the system anymore.
Instead, you should introduce an internal LLM gateway service. This is not a proxy in the networking sense. It is a domain aware service that exposes operations like “summarise underwriting notes”, “extract risk factors”, or “draft internal correspondence”.
Internally, this service owns prompt templates, system instructions, token limits, retry policies, and output validation. Externally, it exposes stable, versioned contracts. This mirrors how Developers treat email, payments, or document rendering. The LLM is powerful, but it is not free form.
Once you centralise LLM access, prompt engineering stops being an ad hoc activity and becomes part of your delivery lifecycle. Prompts should be versioned. Changes should be reviewed. Behavioural differences should be tested against known inputs. In regulated environments, you may even need an approval process for prompt updates.
One effective pattern is to store prompts as structured templates with explicit inputs and outputs, rather than raw text blobs. This makes it easier to reason about what is allowed to change and what is not. Over time, this discipline is what keeps your system stable as models evolve.
Retrieval Augmented Generation Done Properly
Most discussions of RAG stop at embeddings and vector search. That is only half the story. In a production system, the retrieval pipeline is just as important as the model. You need to decide what content is eligible for retrieval, how it is chunked, how it is updated, and how relevance is enforced.
Azure gives you several options here, but Azure AI Search integrates particularly well with Azure OpenAI. It supports vector search, hybrid scoring, private endpoints, and managed identity. The critical point is that retrieval should happen before the model sees anything. The model should never be trusted to “remember” or “decide” what context it needs. You provide it with a constrained, curated slice of data and ask it to operate within that boundary. This is how you avoid hallucinations becoming system behaviour.
Failure Modes You Must Design For
LLMs do not fail like databases, message queues or HTTP APIs. If you treat them as just another REST dependency, you will build something that looks stable in testing and becomes unpredictable in production.
The first class of failure is load-related degradation, not hard outages. LLM services tend to fail slowly. As concurrency increases, token queues grow, response times stretch, and eventually requests start timing out upstream. From the caller’s perspective this does not look like a clean failure. It looks like sporadic latency spikes, partial responses, and workflows that suddenly take seconds or minutes longer than expected. If you do not impose strict per-request timeouts and concurrency limits, a small surge in usage can cascade through your system and block unrelated work.
The second failure mode is cost-amplified failure. Traditional services usually fail cheap. An LLM can fail expensively. A subtle prompt change, a retrieval bug, or an unbounded user input can multiply token usage overnight. Nothing crashes, nothing throws an exception, but your bill explodes. This is one of the most dangerous characteristics of LLM systems because it bypasses most operational alarms. Architecturally, this means you must treat token usage as a first-class resource. Hard caps, per-operation budgets, and enforced truncation are not optimisations, they are safety rails.
The third class of failure is semantic drift. LLMs can be up, healthy, and responding successfully while still being wrong in a way that breaks your system. A model version update, a backend optimisation, or even a temperature tweak can subtly change behaviour. Summaries become less precise. Classifications start misfiring. Edge cases creep in. Unlike traditional regressions, these failures do not show up as errors. They show up as business logic slowly becoming unreliable. This is why prompt versioning, golden test cases, and behavioural monitoring matter. You are not just testing availability, you are testing meaning.
Another critical failure mode is partial unavailability. LLMs often fail unevenly. Streaming might work while full completions time out. Small prompts succeed while larger ones fail. One deployment remains responsive while another degrades. Your architecture needs to handle this without collapsing. That usually means isolating LLM calls behind a boundary that can apply routing, fallback models, or degraded modes without forcing every caller to understand those details.
Then there is dependency amplification. Many LLM calls depend on other systems before the model is even invoked. Retrieval pipelines, embedding generation, vector search, prompt construction, and policy checks all sit upstream. A failure in any one of these can make the LLM appear unreliable, even though inference itself is healthy. This is why treating the LLM as a single black box is a mistake. You need visibility and control over each stage of the pipeline, and the ability to short-circuit or degrade when part of that pipeline fails.
All of this leads to a hard architectural question, what happens when the LLM is not available, not fast enough, or not trustworthy enough? There is no universal answer. In some systems, you return cached or last-known-good output. In others, you fall back to a simpler rules based path. In some workflows, you block progress and surface a clear error because proceeding would be worse. The key point is that this decision must be made explicitly, per capability, not implicitly by letting timeouts bubble up. Circuit breakers are essential, but they are not enough on their own. A breaker that simply stops calls does not solve the user experience problem. You need to define degraded behaviour that still makes sense in your domain. That is why these decisions belong at the architectural level. They define system behaviour under stress, not just how code handles exceptions.
The final mistake is assuming that retries are always helpful. With LLMs, retries often amplify the problem. If the model is slow due to load, retrying increases load. If the failure is semantic, retrying produces the same wrong answer. Retries should be rare, bounded, and context-aware. Blind retries are a liability.
I guess the takeaway here is simple but uncomfortable. An LLM is not an optional enhancement once it sits on a critical path. It is a core dependency with unique failure characteristics. You must design for those characteristics deliberately, or the system will design itself under pressure.
Treat the LLM like any other critical dependency, because operationally and financially thats exactly what it is.
Observability Beyond Token Counts
The first thing you need is latency distribution, not average latency. LLM performance degrades unevenly. Median latency may look fine while tail latency quietly doubles. This usually happens under load, when token queues back up or streaming responses stall. If you only watch averages, you will miss the early warning signs. P95 and P99 latency per operation tell you when the system is becoming unreliable long before it outright fails. This is especially important if LLM calls sit on synchronous user-facing paths.
Token usage must be tracked per capability, not per service. “Total tokens per day” tells you very little. What you actually need to know is which operation consumed them. Summarisation, classification, extraction, drafting, routing, each of these has a very different expected token profile. When one of them spikes, it is almost always a design regression, a prompt change, or a retrieval issue. Without per-operation attribution, cost overruns appear mysterious and uncontrollable.
Another critical dimension is prompt version awareness. LLM failures are often self-inflicted. A well-intentioned prompt tweak increases verbosity, weakens constraints, or causes the model to echo input. Nothing crashes. Token usage rises. Latency increases. Behaviour subtly shifts. If you cannot correlate requests and outputs to a specific prompt version, you cannot diagnose this class of failure. Prompt versions are effectively code. They must be observable as such.
Error rates also need reinterpretation. LLM systems do not fail with clean 500s. Many failures surface as timeouts, partial responses, truncated output, or invalid structured responses. You need to classify errors semantically. Was the response incomplete. Did it violate schema. Did it exceed budget. Did it arrive too late to be useful. These distinctions matter more than HTTP status codes.
One of the most overlooked signals is downstream impact. An LLM can appear healthy while degrading everything around it. Slower responses increase queue depth. Larger outputs stress storage or messaging systems. Poor classifications send workflows down the wrong path. Observability needs to extend beyond the model call itself and into what happens next. If LLM output feeds automated decisions, you should monitor reversal rates, human corrections, or escalation frequency. These are behavioural metrics, not technical ones, and they are often the first indication that something has gone wrong.
Logging deserves special care. Logging full prompts and responses is tempting, and in early experiments it can be useful. In production systems, it is often a liability. Prompts may contain sensitive data. Outputs may contain inferred or derived information that creates compliance risk. A safer pattern is to log metadata instead of content. Token counts, input and output sizes, hashes of prompts, prompt identifiers, model version, latency, and validation outcomes usually provide enough signal to diagnose issues without storing raw text. When deeper inspection is required, targeted sampling with strict access controls is safer than blanket logging.
All of this becomes dramatically easier when LLM access is centralised. If every team calls the model directly with their own prompts, observability fragments immediately. Metrics lose consistency. Prompt versions are unknown. Cost attribution becomes political. Centralisation does not mean slowing teams down. It means giving them a stable, observable platform instead of a shared bill. The uncomfortable truth is that LLM observability is closer to monitoring business logic than infrastructure. You are not just watching whether the system is up. You are watching whether it is behaving as intended. Token counts are a starting point. Serious systems go much further.
When You Really Need to Self Host Models
There are legitimate cases where managed inference is not enough. Offline environments, extreme data sovereignty requirements, or deep fine-tuning at the weight level may push you toward self hosted models on AKS with GPU nodes. The important thing is that this is an intentional step, not an accident. The same principles still apply. Private networking. Managed identity where possible. Centralised access. Clear ownership. The mistake is thinking that self hosting is more local by default. Without discipline, it is often less secure and less predictable than a managed service.
The End State You Should Aim For
A successful local LLM on Azure does not feel like AI.
It has an endpoint name that looks like an internal service. It has dashboards. It has quotas. It has owners. Changes are deliberate. Behaviour is predictable.
When you reach that point, the model itself becomes interchangeable. You can swap versions, introduce new deployments, or even change inference backends without rewriting your application.
That is the real value of doing this properly.
If you build it this way from the start, you are not experimenting with LLMs. You are operating them.




